
由于应用的多样性以及每个应用对功耗和性能的高特定要求,设计AI/ML推理芯片正成为一个巨大的挑战。
简而言之,一种尺寸并不适合所有人,也不是所有的应用程序都能够承受定制设计。例如,在零售店跟踪中,对于经过某个过道的顾客,允许5%或10%的误差幅度是可以接受的,而在医疗诊断或汽车视觉中,精度需要显著提高。但结果的准确性将以功耗和性能以及设计复杂性为代价。此外,始终在线/无停机、吞吐量、数据流和管理、延迟和可编程性。在人工智能中,准确度是正确答案概率的度量,定义为正确预测数除以预测总数。例如,如果100个样本中有85个样本被正确预测,则准确率为85%。Palo Alto Networks的高级数据科学家Venkatesh Pappakrishnan认为,ML算法几乎不可能达到100%的预测准确率。一般来说,一个好的ML算法,准确率在80%到85%比较现实。达到近95%的准确率需要巨大的努力、时间、更深的领域知识以及额外的数据工程和收集。最有可能的是,你可以发布一个准确率在75%到85%的模型,然后进行改进。另一个关键指标是精度,直接影响精度。在实现推理解决方案时,开发人员使用int(x)格式来表示整数。对于边推理,通常是int8或更低。1表示1位整数,而8表示Int8位整数。比特值越高,精确度越高。一个简单的类比就是一张照片的像素数。像素越多,分辨率越高。在推理上,int8会比int4产生更高的准确率。但是它也需要更多的内存和更长的处理时间。在一次测试中,NVIDIA证明int4的精度比int8快59%。Arm物联网和嵌入式、汽车和基础设施业务线的细分市场营销总监帕拉格·贝拉卡(Parag Beeraka)表示:“准确度和精度要求范围很广,这完全取决于用例。”“比如AI/ML用于实时语言翻译,那么你真的需要有更高的准确度和精度,才能让它容易理解。但是,如果AI/ML用于对象识别用例,所需的精度越高,将AI/ML模型映射到低功耗AI芯片的过程就越复杂。您可以通过牺牲一些精确性和准确性来降低复杂性。这就是为什么你会看到许多低功耗边缘AI芯片使用int8(8位)格式,但你会看到许多较新的ML技术也支持更低的(1位),所以何时何地进行这些权衡取决于应用和用例。”Cadence Tensilica AI DSP产品营销总监Suhas Mitra表示:“准确度和精度在很大程度上取决于系统级用例。不同的指标用于确定应用程序可以承受的准确度/精度。例如,运行在低功耗边缘物联网设备上的图像分类,与基于汽车自主性的系统相比,可能能够容忍更低的精度,而汽车自主性要求更高的精度。所有这些不仅影响了软件的设计方式,也影响了硬件。GPU,FPGA还是ASIC?
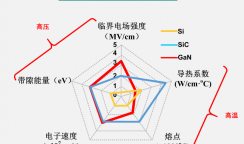
在AI/ML芯片上运行的是软件。随着时间的推移,各种AI/ML算法和实现得到了发展。过去,算法会在CPU上运行。然而,越来越多的这种软件被嵌入到芯片中。对于边缘应用,正在部署特定的软件模块。“人工智能算法跨越多种功能,”西门子EDA的HLS平台主任Russ Klein说。“其中一些非常适中,可以在嵌入式处理器上轻松运行,而另一些则庞大而复杂,需要特殊的专用硬件来满足性能和效率要求。许多因素有助于确定人工智能算法的部署位置,但软件、现成的加速器或定制硬件的软硬件权衡与大多数嵌入式系统类似。”到目前为止,软件是实现任何功能的最灵活、适应性最强的方法,并且它提供了最廉价的开发。“软件是‘面向未来’的,”克莱恩说。“CPU会运行任何尚未被发现的推理算法。基于CPU的系统通常可以在部署时进行更新。然而,软件可能是部署人工智能算法最慢、最节能的方式。”推理芯片目前使用的有CPU,GPU,FPGA,ASIC。虽然CPU因其灵活性仍在一些AI/ML推理应用中使用,但GPU、FPGA和ASIC因其更高的性能效率已成为深度神经网络(DNN)和卷积神经网络(CNN)的首选。它们的吸引力在于它们在各种新应用中的不断增长。GPU有非常高效的并行处理和内存管理。他们通常使用C/C++高级语言,在高性能DNN和CNN应用程序中工作良好,如数据中心和自动驾驶。然而,对于边缘推理应用,如可穿戴设备和安全摄像头,GPU可能会消耗过多的功率。相比之下,FPGA提供可编程I/O和逻辑模块。用HDL等工具映射AI/ML模型的有效方法对于推理应用非常重要。高效的内存管理也很重要。Flex Logix的IP销售、营销和解决方案架构副总裁安迪·亚罗什(Andy Schmidt)表示,“低功耗、可编程性、准确性和高吞吐量是推动高效边缘人工智能解决方案的四种相互冲突的力量。”“采用特定模型加速器的ASIC解决方案将永远是最节能的解决方案,但将失去可编程性。多年来,嵌入式处理器得到了增强,以增加AI模型所需的乘法和累加(MAC)处理,但它们不具备满足高精度要求的MAC密度。”亚罗什说,研究人员和系统设计人员现在正在探索各种方法,将eFPGA用于人工智能处理解决方案。“正在研究的方法包括特定型号的处理器定制指令,其中指令集可以根据型号的不同而变化。另一方面,该指令集的多功能性可以将eFPGA DSP MAC用于更传统的基于FPGA的加速器,并利用在FPGA的逻辑结构中非常有效地运行的二进制或三进制模型,同时保持合理的精度。利用eFPGA的可重编程性和灵活性使AIoT设备成为可能,最终客户可以为他们的应用选择可编程性、功耗、性能和精度的正确组合,”他说。“将eFPGA用于人工智能还为最终用户提供了更高的安全性,因为他们的专有指令或加速器可以在制造后在安全的环境中编程。没有人需要看到他们的秘密电路。使用PUF技术的比特流加密,例如我们最近与Intrinsic ID的合作,为比特流保护增加了更高的安全级别。”通过它们的结构——不同于GPU和FPGA——ASIC是为特定应用定制的。根据复杂程度和工艺节点,设计可能非常昂贵。例如,在设计过程的后期进行更改以适应更新的协议或工程变更单可能会推高这些成本。另一方面,由于特定应用的专用功能,该架构更加节能。“如果低功耗是关键标准之一,那么ASIC是构建低功耗人工智能芯片的正确解决方案,”Arm的Parag说。“如果终端设备是小批量产品,eFPGA可能是一个不错的选择。然而,这可能会转化为更高的成本。部分细分市场可以满足eFPGA的需求,但大部分是ASIC。”安全与新兴技术中心发布的报告显示,与CPU技术相比,ASIC在效率和速度上的表现高达1000倍,而FPGA的表现高达100倍。GPU提供高达10倍的效率和100倍的速度。这些芯片大多可以达到90%到几乎100%的推断准确率。(见下表1)表1:AI/ML推理中各种芯片技术的比较。资料来源:Saif M. Khan/安全和新兴技术中心
“专门的加速器,如GPU、张量处理单元(TPU)或神经处理单元(NPU),可以提供比通用处理器更高的性能,同时保持传统处理器的大部分可编程性,并显示出比CPU更高的推理效率。但随着专业化程度的提高,下一代人工智能算法可能会面临不能正确操作组合的风险。然而,为特定人工智能算法定制的专用eFPGA/FPGA或ASIC加速器的实现可以满足最严格的要求。关键实时应用,如自动驾驶或那些必须从能量收集中获取能量的应用,可以受益于定制开发的加速器。但是自定义加速器的开发成本也是最高的。如果它们没有一定数量的内置可编程逻辑,它们可能很快就会过时。”FPGA或eFPGA保留了一定的可重编程能力,但代价是比同等的ASIC功耗更高、性能更低,”西门子EDA的Klein说。像大多数设计一样,可重用性降低了设计成本。在某些情况下,多达80%的芯片可能会在下一个版本中重用。对于推理设备来说,能够重用IP或芯片的其他部分也可以显著缩短上市时间,这一点很重要,因为算法几乎是不断更新的。虽然通用芯片(如CPU)可以通过不同的软件或算法进行推理,但代价是较低的性能。另一方面,除非实现非常相似的应用,否则ASIC的可重用性会受到更多限制。它是中间的FPGA或e FPGA,具有最标准的逻辑,并允许以最小的努力对软件进行重新编程。Arm的帕拉格表示:“要让一些设计可以被AI重用,需要考虑很多因素。" "其中包括可扩展的硬件AI/ML加速器IP(具有良好的模拟和建模工具),在可扩展的硬件加速器IP上支持不同框架的软件生态系统,以及覆盖最广泛用例的多框架支持模型。“其他人同意。”主要考虑的是如何快速绘制新的人工智能模型拓扑结构,”Cadence的Mitra说。有时我们会陷入从硬件中挤出每一盎司的压力,但人工智能网络变化如此之快,以至于优化每一行逻辑可能会产生相反的效果。对于可重复使用的设计,它应该能够处理一个大而复杂的数学函数,包括各种格式的卷积、激活函数等。“比例因子
今天的AI/ML推理加速器芯片设计面临着将高性能处理、内存和多个I/O封装在一个小封装中的挑战。但是高性能处理会消耗更多的功率并产生更多的热量,因此设计团队必须在性能、功率和成本之间取得平衡。增加传感器融合(如音频、视频、光线、雷达)将使其更加复杂。但至少可以利用一些行业经验。“解决视频/图像接口中传感器融合问题的一个简单方法是采用MIPI标准,”Mixel营销和销售高级经理Justin Endo说。“最初,MIPI用于移动行业。现在已经扩展到覆盖很多消费者和AI/ML边缘应用。例如,推理处理器Perceive Ergo芯片有两个MIPI CSI-2和两个CPI输入和一个MIPI CSI-2输出,支持两个同步图像处理流水线——一个使用4通道MIPI D的高性能4K -PHY CSI-2 RX实例和一个使用2通道MIPI D-PHY CSI-2 RX的2K/FHD实例。”感知的Ergo芯片是一个ASIC,在视频推理应用中20mW可以实现30 FPS。其他AI/ML芯片可能消耗2到5瓦,具体取决于芯片架构。在家用安全摄像头等电池供电设备中,低功耗非常重要。低功耗使得电池的使用寿命更长,在可穿戴应用中,也有助于设备在更低的温度下运行。“效率非常重要,”感知公司首席执行官史蒂夫·泰格说。“当需要更高的性能时,功耗的差异会更明显。比如视频性能提升到300 FPS,Ergo芯片的功耗会在200 mW左右,而其他芯片的功耗可能在20W到50 W之间,这个可能很重要。”然而,并不是每个人都以同样的方式衡量性能和功率。Syntiant是一家始终在线的推理ASIC供应商,在tinyML进行的推理Tiny v0.7测试中展示了其性能。在一次测试中,其产品的延迟时间分别为1.8和4.3毫秒,而其他产品的延迟时间为19到97毫秒。在能源/功耗类别中,Syntiant的得分为35 J和49 J,而其他公司的得分为1482J至4,635,根据Syntiant的说法,这些芯片可以在140uW下运行全面的推理运算。但是比较这些芯片是一个雷区。没有通用的标准来衡量AI/ML的推理性能。因此,重要的是让用户了解芯片在特定领域实际工作负载下的性能,并将其放在对终端市场重要的背景中。在某些应用中,性能问题可能不如功耗问题严重,而在其他应用中,情况可能正好相反。精度和性能也是如此。为了达到更高的推理精度,需要更复杂的算法和更长的执行时间。结论
平衡所有这些因素是 AI/ML 推理的一个持续挑战。什么是正确的芯片或芯片组合取决于应用程序和用例。在某些情况下,它可能是完全定制的设计。在其他情况下,它可能是现成的标准部件和重复使用的 IP 的某种组合,它们拼凑在一起以满足非常紧迫的期限。
“人工智能算法变得越来越复杂,计算量和参数呈指数级增长,”西门子 EDA 的 Klein 说。” 计算需求远远超过芯片改进,促使许多设计人员在部署 AI 算法时采用某种形式的硬件加速。对于某些应用,商业加速器或神经网络 IP 就足够了。但要求最苛刻的应用程序需要自定义加速器,以将开发人员从 ML 框架快速带入专门的 RTL。高级综合 (HLS) 提供了从算法到面向 ASIC、FPGA 或 eFPGA 的硬件实现的最快路径。HLS 减少了设计时间,或许更重要的是,它证明了 AI 算法已在硬件中正确实施,解决了许多验证挑战。”










 在线
在线
 咨询
咨询
 关注
关注